If you find the title of this blog a bit weird – you might be right or wrong it depends on the context. ????
GenAI has exploded and so too has the need for efficient data management and retrieval systems, leveraging vector databases and software-defined storage to enhance the capabilities of Retrieval Augmented Generation (RAG) models.
When I asked Google and ChatGPT “What does RAG stand for?”, both first replied “Red, Amber, Green” – the international color codes for traffic lights – and both Google and ChatGPT are correct. The problem is that I didn’t give either search platform enough context to the question to get the answer I am seeking. I’m asking about RAG in the context of AI – meaning if I ask “What is RAG AI?” then the reply from both would be that RAG stands for Retrieval Augmented Generation.
And now to something completely different…
The first car was invented in 1886, and no one could deny that it was a great invention. To think about taking a gas engine and placing it on a wood or metal frame with wheels sounds ingenious and mind-blowing. But it wasn’t until the invention of the pneumatic tire by John Boyd Dunlop in 1888, that cars really started to be drivable and became successful. Because as much as it was a new and smarter way to move around, all the cars still used rubber or metal tires, making the ride very uncomfortable. Just imagine, a vehicle that is much faster than a horse with a wheeled cart, but with wheels that offer no sort of shock resistance. Ouch! All this ended with the pneumatic tire. The ride became much smoother, making the car as a product a lot more appealing.

And how does all this history lesson relate to AI and RAG?
Just like LLMs and how ChatGPT, Co-Pilot, or Gemini are amazing new ways to interact, ask questions, and feel like talking to a human, this ingenious invention needs a little push (or a “pneumatic tire”) in order for it to be more context-oriented or to our point, more subject or company-oriented – and that is exactly what RAG is all about.
As mentioned earlier, RAG stands for Retrieval Augmented Generation, it is an NLP (Natural Language Processing) method that combines both generative and retrieval AI.
The massive training that these “engines” have done is based on Foundation Models that allow you to “feel” as if you are having a conversation with a human, but products that are built on this training have a few flaws:
- They are “stuck” in time. Once training is done, the data these products have trained on is all they have to work with. This might lead to an effect that is sometimes referred to as “hallucination” where the reply might seem reasonable, but it might not be true or complete (remember that these products are trained to reply with “something”, even “don’t know” is a reply). For example, if you asked, “Can I use Lightbits in the public cloud?” if the training was done before 2023, the reply would probably be negative. This is incorrect since Lightbits software-defined storage can be run on both AWS and Azure.
- Foundation models are costly to produce, in fact only a handful of companies in the world have the infrastructure resources to create and run this massive training that can take from days to months.
- These products have no knowledge of your company or what your line of business is, or the context of your application. That is exactly where RAG and vector databases come into play.
So how does RAG (or vector databases) work and how does it help with “domain-specific” questions?
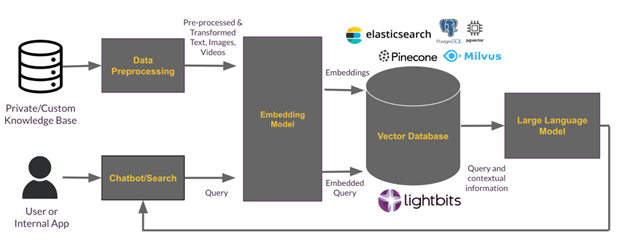
Think about RAG as your very own domain-specific AI embedding model. You would use a process to “embed” your domain-specific data derived from your knowledge base documents, support chat, white papers, website, etc. This data gets “vectorized” into a database, meaning each vector will have some specific meaning that can be searched semantically and contextually. It is important to note that depending on several factors like the size of data, the embedding process can run on either CPUs or GPUs.
Today, there are several companies whose main product is a vector database, such as Milvus and Pinecone. Additionally, some database products now offer built-in vector store capabilities, like Redis, ElasticSearch, and even Oracle. There are also extensions that allow regular databases to hold vector data, such as pgvector for PostgreSQL or VectorDB for Python.
RAG and Lightbits Software-Defined Storage
So how does Lightbits software-defined storage fit into this vision of using RAG for domain-specific AI?
Lightbits is the fastest block storage in both private and public clouds.
Today, most of the demos that you see for vector databases are fairly small and textual-based. For my example, you would vectorize your KB articles, white papers, website, and maybe even your website AI chatbot (learning from learning if you think about it). The vector data can, in most cases, reside in your server/VM/pod memory, but there are two issues with this:
- Memory data is volatile and you need to protect it. In some cases, you can do that at the database level or you can use low latency, fast NVMe storage like Lightbits to keep your data resilient and accessible. Many people will combine both methods, resiliency at the database level and lower at the stack level (storage) for maximum performance and protection.
- In my opinion, the bigger point to consider is that the datasets that are used today for demos are fairly small. What comes next after your textual data is embedded? For example, say you are a large bank and you want to add all your recorded phone calls, and all the internal video meetings (like training), as well as sorts of images or records, we’re talking about a giant leap of data to consume into a vector database that will not fit into memory. This results in the same problem generic databases have, keep the “hot” data in memory and the “cold” data in storage. However, since the interactions with AI are quite random, you’ll need very fast access to “cold” vectors. Again, this is exactly where a high-performance software-defined storage platform like Lightbits comes into play.
Conclusion:
In this blog post, we discussed how RAG, using vector databases, can help your company to build a more accurate and scalable GenAI application that is tuned to a specific domain or more “true” to your company products. We mentioned a few of the vector databases offered currently in the market and explained why it is important to architect your data platform from the ground up with a fast, scalable block storage solution like Lightbits. Lightbits architecture is attuned to the performance and scalability requirements of AI and will not slow down your GenAI application once you start to embed more and more data.

