Embarking on the journey of AI/ML as a product manager is like setting sail into uncharted waters − it’s thrilling, full of surprises, and absolutely rewarding! And the best part? My voyage has just begun.
I’ve been having some great conversations with industry analysts and experts lately. We’ve been exploring the use cases and potential of Software-Defined Block Storage, especially when it comes to handling AI/ML workloads. It’s fascinating how Software-Defined Storage (SDS) is emerging as a go-to solution for the demanding storage needs for these use cases.
A New Approach to Storage
In the realm of AI/ML and GPU-intensive workloads, the need for efficient, high-performance, and robust storage solutions is paramount. These workloads involve processing vast volumes of data at high speeds. While local NVMe™ storage is widely used today for AI/ML due to its high performance, it has its limitations. It’s not the most efficient when it comes to resource utilization, and it struggles with scalability, sharing capabilities and data protection. This is where Software-Defined Block Storage comes into play. It’s designed to address these challenges, providing a solution that not only matches the performance of local NVMe but also offers superior efficiency, scalability, and data protection. Disaggregating storage from compute allows resources to be shared and scaled as needed, making a significant impact in the world of AI/ML and GPU-intensive workloads.
The Role of Software-Defined Block Storage
While shared filesystems and object-based storage are commonly used for AI/ML and GPU workloads, Software-Defined Block storage also has its place, especially when these workloads begin to scale. The Lightbits cloud data platform is one option as with its high performance and low latency, it becomes a viable option for handling the increased data processing demands of larger AI/ML projects in their various stages of the pipelines. And when block storage is disaggregated, it brings an added level of flexibility and scalability that can be a game-changer for these workloads.
Let’s consider a real-world scenario based on my discussions. Imagine a company embarking on an AI project. During the initial stages or proof-of-concept justifications, they might opt for local storage as a quick solution to test and validate ideas during the data preprocessing stage. This approach, while simple, is limited to a single system and can quickly become a bottleneck as the project scales.
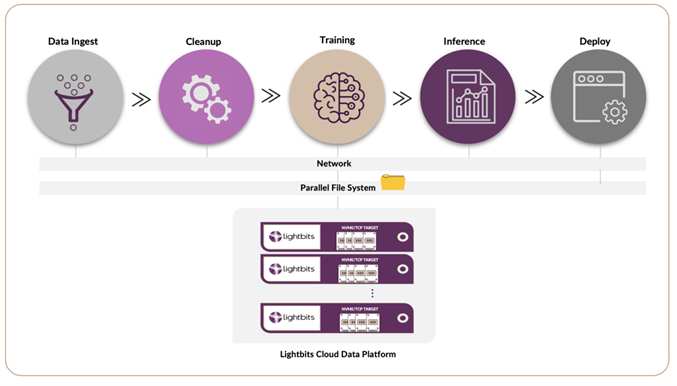
As the project matures and the need for unstructured data support grows, the limitations of local storage become more apparent. AI/ML workloads are not just a single workload. They involve a variety of tasks such as data ingestion, cleanup, training, inference, deploy and active archiving. While block storage is ideal for training data, the majority of workloads happen on file-based systems, like local or parallel file systems. A significant portion of the data that comes into these AI projects is file-based, with a smaller percentage being object-based. This is why we are seeing file and object storage merging into a single product market to support more options and avoid making choices that are relatively slow storage systems.
Interestingly, a trend we’re noticing is that organizations often prefer to bring their own filesystem and run it on standard fast block storage. One such example is Lustre which is a common choice. This approach allows organizations to leverage the high-performance benefits of block storage while still enjoying the flexibility and accessibility of a parallel file system.
Moreover, to avoid overloading the CPU and to maximize GPU utilization, machine learning tasks often operate on a cluster of NVMe servers and storage units, rather than relying on local storage or single controllers. This is where disaggregated storage shines. It supports this distributed design architecture and offers the flexibility and scalability required to manage dynamic AI/ML workloads. It allows the company to start small and scale as needed, providing a level of investment protection, especially if the AI project doesn’t take off as expected.
However, it’s also important to note that only around 10% of the data is mostly active in many cases. Therefore, a solution for managing data that isn’t frequently accessed, like active archive capabilities, is crucial. While not all block storage inherently provides this feature, it can be achieved with a data management solution on top of block storage.
So, in this scenario, the company can leverage Software-Defined Block Storage to overcome the limitations of local storage, efficiently manage diverse AI/ML workloads, and ensure optimal GPU utilization. This flexibility and scalability are game changers, allowing the project to scale smoothly without compromising on performance.
Looking Ahead
As AI/ML continues to permeate various industries, the demand for flexible, scalable, and high-performance block storage solutions will only grow. Whether it’s for data processing at the edge, training and inference for AI/ML workloads, or analytics, high-performance and cost-effective storage such as NVMe over TCP is poised to play a pivotal role in the AI/ML and GPU market.
In conclusion, Software-Defined Block Storage like Lightbits is more than just a storage solution; it’s a strategic enabler for AI/ML workloads. By offering unparalleled flexibility, scalability, and performance, Lightbits is helping organizations unlock the full potential of their AI/ML projects, driving innovation, and paving the way for a future powered by intelligent insights. As my recent conversation with industry analysts underscored, the future of AI/ML and GPU workloads is closely tied to the evolution of high-performance and scalable storage solutions like Lightbits.
So, there you have it − my insights on the potential of Software-Defined Block Storage such as Lightbits for AI/ML and GPU-intensive workloads. Now, over to you. What has been your experience with Block Storage in handling AI and ML workloads? I’d love to hear your thoughts.

