The ability to access and analyze information is crucial in today’s data-driven landscape. Elasticsearch has emerged as one of the leading solutions for distributed search and analytics, capable of handling petabytes of data in milliseconds. However, the performance of Elasticsearch can only be as good as the infrastructure it runs on. This is where Lightbits shines with its innovative disaggregated software-defined storage solutions.
By separating storage resources from compute resources, Lightbits not only enhances the scalability and storage consumption efficiency, but also complements the dynamic nature of Elasticsearch deployments. In this blog, we will explore how Lightbits’ software-defined storage can transform the performance of an Elasticsearch environment, ensuring that the data is not only quickly accessible, but also secure, scalable, and cost-effective.
Elasticsearch Overview
Elasticsearch is a modern distributed, open-source search and analytics engine built on Apache Lucene and developed in Java. Its primary purpose is to allow vast amounts of data to be stored, searched, and analyzed quickly and in near real-time. It can efficiently store and index all types of data such as structured or unstructured text, numerical data, or geospatial data in a way that supports fast searches.
Elasticsearch offers speed and flexibility to handle data in a wide variety of use cases, including:
- Adding a search box to an application or website.
- Storing and analyzing logs, metrics, and security event data.
- Using machine learning to automatically model the behavior of data in real-time.
- Using Elasticsearch as a vector database to create, store, and search vector embeddings.
- Automating business workflows using Elasticsearch as a storage engine.
- Managing, integrating, and analyzing spatial information using Elasticsearch as a Geographic Information System (GIS).
- Storing and processing genetic data using Elasticsearch as a bioinformatics research tool.
In essence, instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents.
Lightbits Disaggregated Software-Defined Storage Overview
Lightbits represents a paradigm shift in how storage resources are managed and utilized in modern data centers. Lightbits’ unique disaggregated, software-defined, NVMe® over TCP, block storage architecture – combined with Intelligent Flash Management and enterprise-rich data services – makes it the only complete cloud data platform that’s easy to provision, simple to manage, highly scalable and performant, and cost-efficient.
At its core, it leverages NVMe over TCP (NVMe/TCP) storage protocol technology, which was invented by Lightbits, to deliver low-latency, high-performance block storage over a regular Ethernet network. This not only reduces the cost and complexity compared to other technologies like Fibre Channel or Infiniband but also democratizes access to high-speed NVMe storage.
The software-defined nature of Lightbits’ solution means it can be deployed on commodity servers and scaled across a distributed architecture without the need for specialized networking equipment or proprietary hardware. This flexibility combines with advanced features such as Intelligent Flash Management, ElasticRAID, in-line compression, and thin provisioning – all designed to enhance data durability, optimize storage efficiency, and reduce overall operating costs. Lightbits software can be used not only on-premises but also in public clouds like AWS and Azure.
Challenges in Elasticsearch Deployment
Elasticsearch is a powerful tool for managing large and complex data sets, but deploying it effectively presents several challenges. Below are some examples related to storage challenges:
- Intensive Storage Demands: Elasticsearch requires a robust storage solution that can handle not only large volumes of data but also the speed at which data is written and queried. As indices grow and queries become more complex, the storage system must keep up without becoming a bottleneck.
- Performance Bottlenecks: In a distributed environment, Elasticsearch needs to manage data across multiple nodes efficiently. The performance of Elasticsearch is heavily dependent on the speed of data retrieval from storage. Any latency in the storage layer can degrade the performance of search and analytic operations, particularly under heavy load or when scaling out the cluster. This makes the choice of storage system highly critical in optimizing Elasticsearch’s performance.
- Reliability and Availability: Elasticsearch deployments need to be designed for high availability and fault tolerance, to ensure continuous operations and data integrity. This requires configuring Elasticsearch with proper shardings and replicas. We will briefly discuss shardings and replicas in our Findings section.
- Scalability Challenges: As your data volumes grow, Elasticsearch cluster(s) must scale accordingly. However, scaling traditional storage can be disruptive and costly – while scaling direct-attached storage can be costly as well. When deploying Elasticsearch with direct-attached storage, both compute and storage resources must be scaled together.
Lightbits Disaggregated Software-Defined Storage for Elasticsearch
The Lightbits software-defined storage offers a compelling solution for deploying Elasticsearch cluster(s), due to its unique architecture and features that directly address the core challenges of scalability, performance, and reliability. One of the standout features of Lightbits’ solution is its implementation of NVMe over TCP technology. This technology delivers high-performance storage – high throughput and low latency – without the need for specialized hardware to run the I/O intensive operations of Elasticsearch. This approach significantly simplifies provisioning and lowers storage costs, while providing the performance benefits typically associated with more complex systems.
Below are some advantages of running Elasticsearch on Lightbits:
- Scales storage independently of compute resources if more storage is required.
- Lightbits provides consistent performance across various NVMe storage types (i.e., QLC, TLC, etc.).
- Lightbits provides additional compression for any data that Elasticsearch has not compressed.
- Lightbits reduces SSD write amplification by using Intelligent Flash Management to prolong the life of the SSDs.
- For data resiliency, Lightbits uses ElasticRaid within a Lightbits storage node and uses replication within a cluster.
- Lightbits provides better performance and scalability in a large-scale deployment.
- Lightbits provides redirect-on-write (ROW) snapshot technology, which optimizes storage utilization compared to an Elasticsearch snapshot – which makes a copy of the index’s segments and stores them in a snapshot repository.
- Lightbits provides efficient utilization of storage with thin provisioning and TRIM support.
These advantages enhance the scalability of Elasticsearch. As data volumes grow and query complexities increase, Elasticsearch requires a storage solution that can scale efficiently while maintaining high-performance throughput with low latency.
Running the Elasticsearch Rally Benchmark Tool
In our recent studies using the Rally benchmark tool – specifically the cohere_vector and dense_vector tracks – we put Elasticsearch through rigorous performance evaluations to compare direct-attached NVMe storage with Lightbits’ disaggregated software-defined storage solutions.
Despite the inherent advantages of direct-attached storage, such as low latency and high throughput, Lightbits’ storage proved that it can also deliver performance metrics close to that of direct-attached storage in addition to data services mentioned above. This demonstrates Lightbits’ capability to match the speed and responsiveness of direct-attached NVMe storage, which is traditionally favored for high-performance computing environments. More information on Rally benchmarks and tracks can be found here.
The following experiments were performed to get a better understanding of Elasticsearch performance on local NVMe SSDs and Lightbits software-defined storage solutions.
- Run the index and search operations using the dense_vector track with default track settings, to compare local NVMe SSDs and Lightbits high-performance data storage for test purposes.
- Run the index-only operation using cohere _vector track with various client and shard/replica settings on Lightbits data storage solutions.
- Run the index and search operations using the cohere_vector track, with default track settings on Lightbits data storage solutions and a single local NVMe SSD.
Experiment 1
For the first experiment, we configured a single node cluster for both Elasticsearch and Lightbits. This was set up to understand the performance variations between local NVMe SSD(s) and Lightbits software-defined storage. Note that this setup architecture was for our testing purposes only, and not as a recommended deployment configuration.
Figure 1 below shows the physical architecture of a single node cluster for both Elasticsearch and Lightbits.
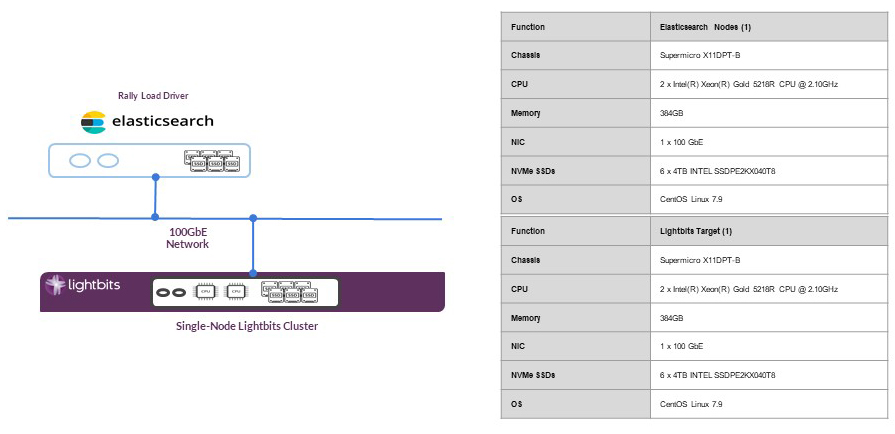
Figure 1: Single-node Elasticsearch and Lightbits Cluster Physical Architecture Testbed
In this performance study, we ran three different test cases with the below storage configurations for the Elasticsearch server:
- 1 x LVM volume striped across six local NVMe SSDs formatted with XFS.
- 1 x physical local NVMe SSD formatted with XFS.
- 1 x Lightbits RF1 volume with ElasticRAID across six SSDs formatted with XFS.
Note: From Lightbits’ perspective, a replication factor of 1 (RF1) means that there is one copy of the volume (primary). A replication factor of 2 (RF2) means that there are two copies of the volume (1 primary and 1 secondary). A replication factor of 3 (RF3) means that there are three copies of the volume (1 primary and 2 secondary).
The graphs below show the results for both document indexing and search operations across the three test cases with the Rally dense_vector track.
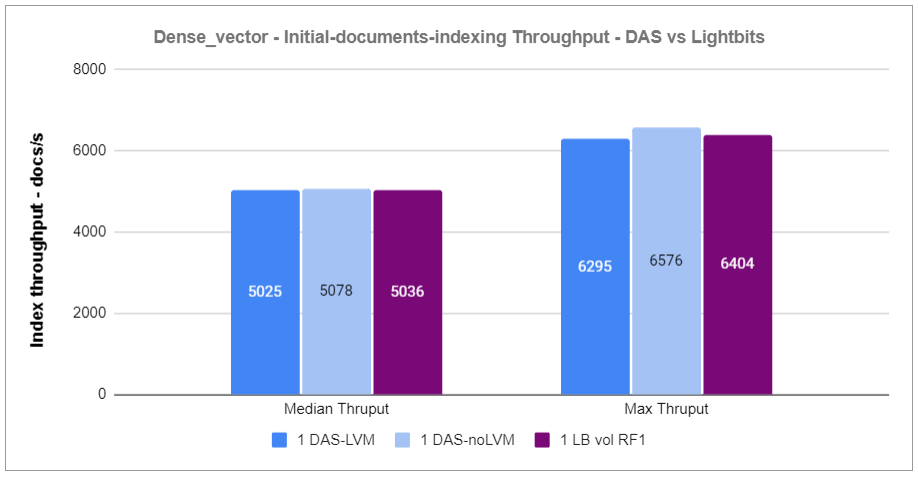
Figure 2: Dense_vector – Initial-documents-indexing Throughput – DAS vs Lightbits
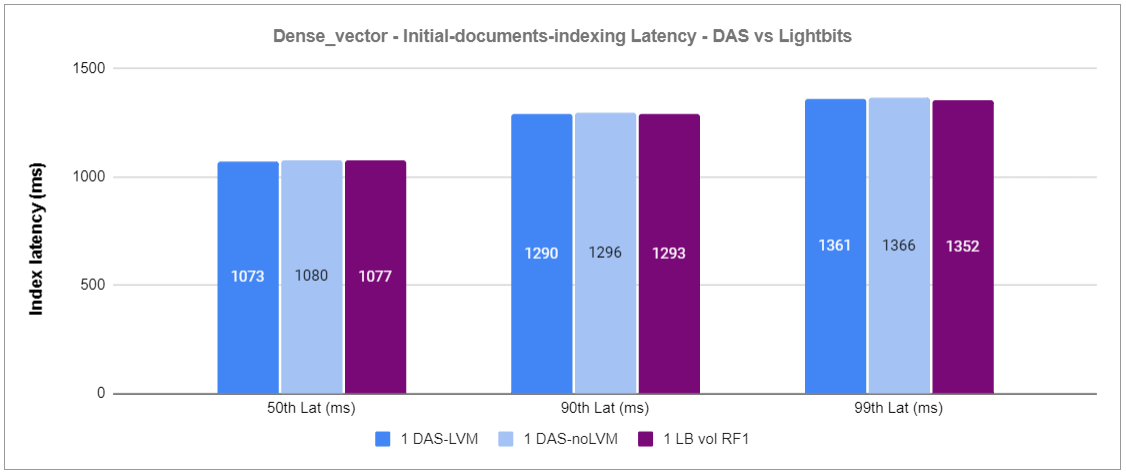
Figure 3: Dense_vector – Initial-documents-indexing Latency – DAS vs Lightbits
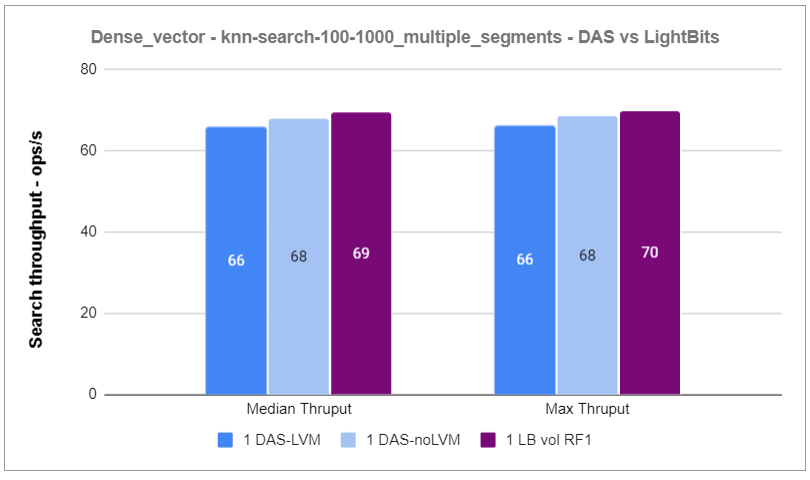
Figure 4: Dense_vector – knn-search-100-1000_multiple_clients Throughput – DAS vs Lightbits
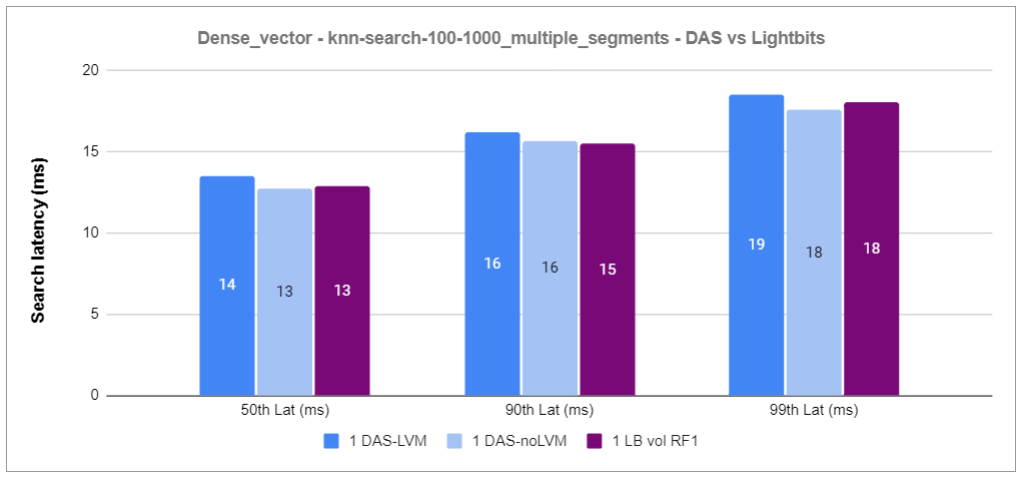
Figure 5: Dense_vector – knn-search-100-1000_multiple_clients Latency – DAS vs Lightbits
Based on the results of the first experiment, we observed that the indexing and search operations performance of a single RF1 Lightbits volume is similar to that of local NVMe SSDs.
Experiment 2
Next, we proceeded to the second experiment. In this study, we used the cohere_vector track to leverage a bigger dataset (500GB+). This was more realistic and enabled us to configure the Elasticsearch cluster with three nodes, and the Lightbits cluster with three nodes as well.
The physical architecture of the three-node Elasticsearch cluster and the three-node Lightbits cluster is shown in Figure 6 below. In this setup, we also used a separate server dedicated to the Rally load driver.
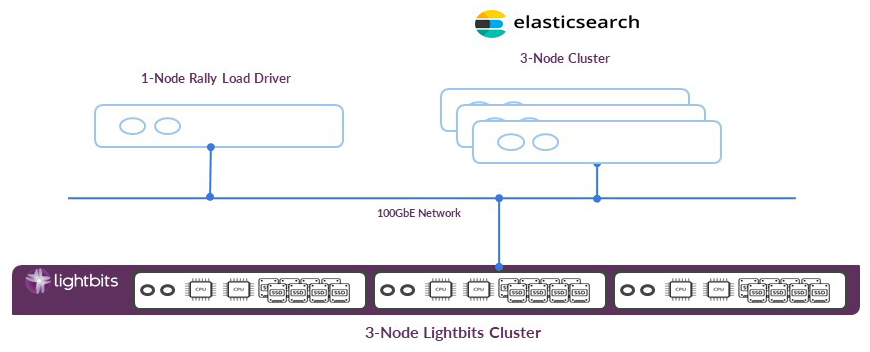
Figure 6: Three-node Elasticsearch and Lightbits cluster
The table below shows the hardware information for the Elasticsearch and Lightbits nodes. Note that the table shows two Lightbits target nodes with CPU and memory configuration different from the other node. This is due to lab equipment availability at the time of the test run.
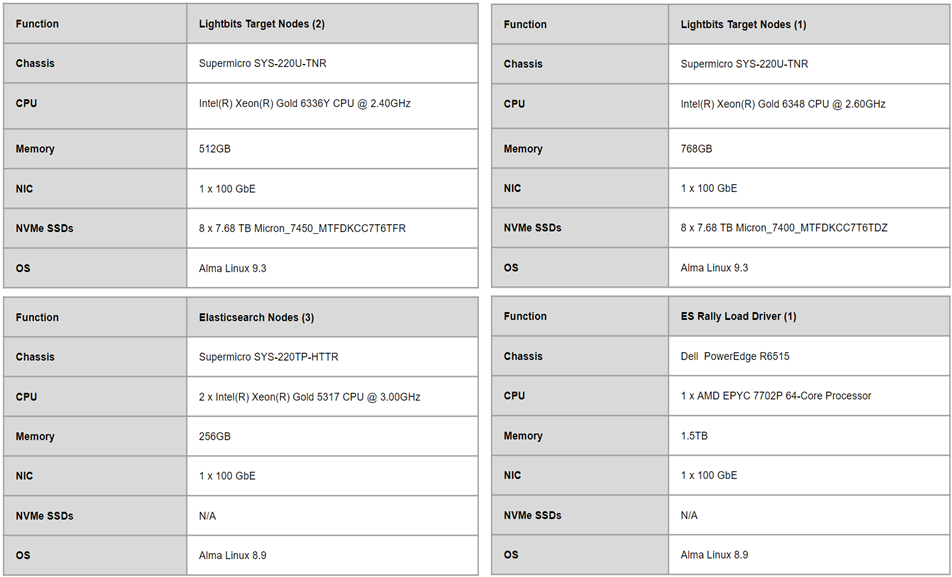
Table 1: Three-node Elasticsearch and Lightbits cluster hardware information
The goal of this experiment was to understand the Lightbits cluster performance when creating volumes with different configurations such as RF2 and RF3, while using various Elasticsearch sharding methods like 3 shards with 1 replica, 6 shards with 1 replica, and 9 shards with 1 replica. In order to increase the workloads, we also ran with 10 clients, 20 clients, and 30 clients. The increase in the number of clients enables us to see how the Lightbits cluster handles the various loads. When running critical business applications on Lightbits cluster(s), we recommend configuring the volumes with RF2 or RF3 to have a higher data resiliency and fault tolerance.
Regarding Elasticsearch sharding, each index is divided into one or more shards – each of which can be replicated across multiple nodes to protect against Elasticsearch node failures by configuring the number of replicas. For this experiment, we only used one replica setting, which is sufficient for the indexing operation. In a production deployment, the number of Elasticsearch replicas can be set to one to safeguard against Elasticsearch node failure. Lightbits will provide the data protection and resiliency through Lightbits data services such as ElasticRAID and replication. More information about Elasticsearch sharding strategy can be found here.
The figures below show the results for max throughput and 99th latency of the indexing operation – with 3 shards, 6 shards, and 9 shards across RF2 and RF3 volumes.
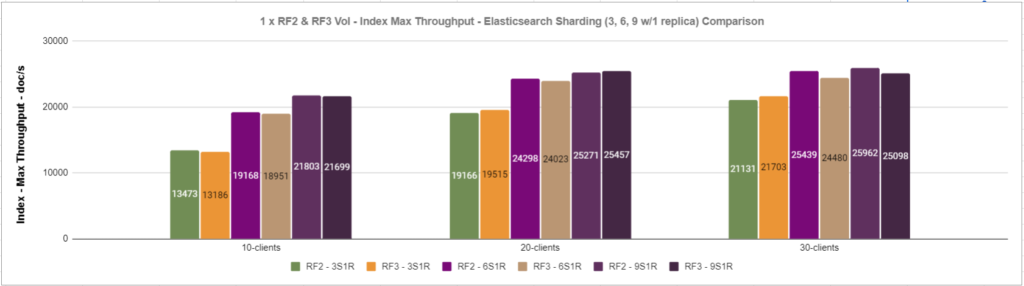
Figure 7: RF2 & RF3 Lightbits volume max throughput for the indexing operation
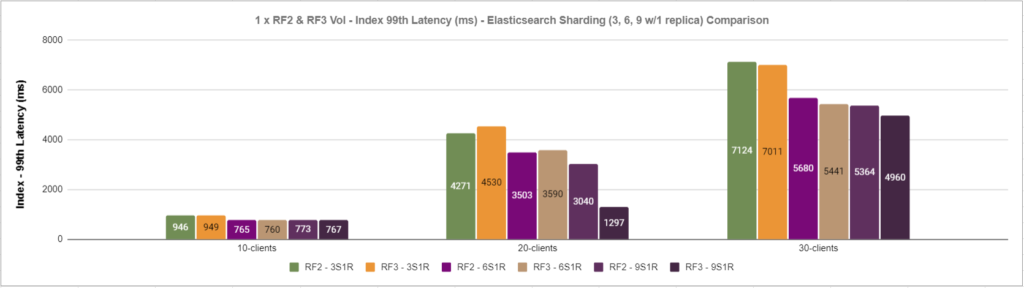
Figure 8: RF2 & RF3 Lightbits volume 99th latency (ms) for the indexing operation
Based on the results and the performance monitoring of the Elasticsearch nodes of this experiment using the “vmstat” command, we noticed that the CPU of the Elasticsearch nodes was running 95+% when scaling out the number of clients and the number of shards. However, the Lightbits cluster nodes were not heavily used. Based on this observation, scaling out the compute resources of the Elasticsearch cluster on this setup would yield more performance in terms of indexing and other operations, without the need for scaling storage.
Experiment 3
Lastly, we wanted to see how a single local NVMe SSD performance compares against a single RF1, RF2, and RF3 Lightbits volume. We know that both setups have different architectures in terms of storage, but we are still interested in the results.
This setup is similar to the first experiment, except that the Lightbits cluster has three nodes with the same hardware configuration as in experiment 2. Again, note that this setup architecture is for testing purposes only and is not recommended for any type of Elasticsearch deployment.
Below is the physical architecture for this experiment.
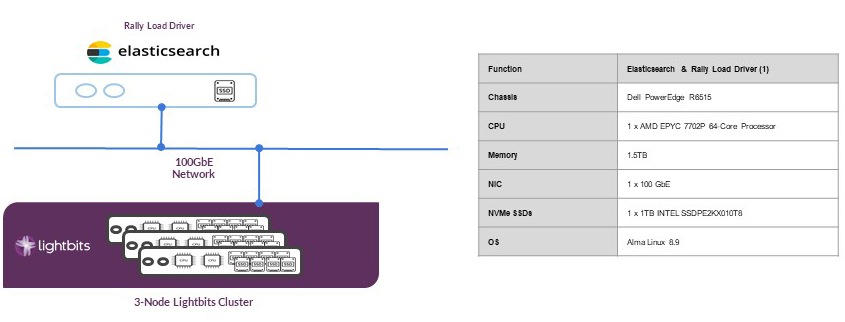
Figure 9: Three-node Elasticsearch and Lightbits cluster
The graphs below show the performance results of the indexing and search operations of the cohere_vector track using the track default settings.
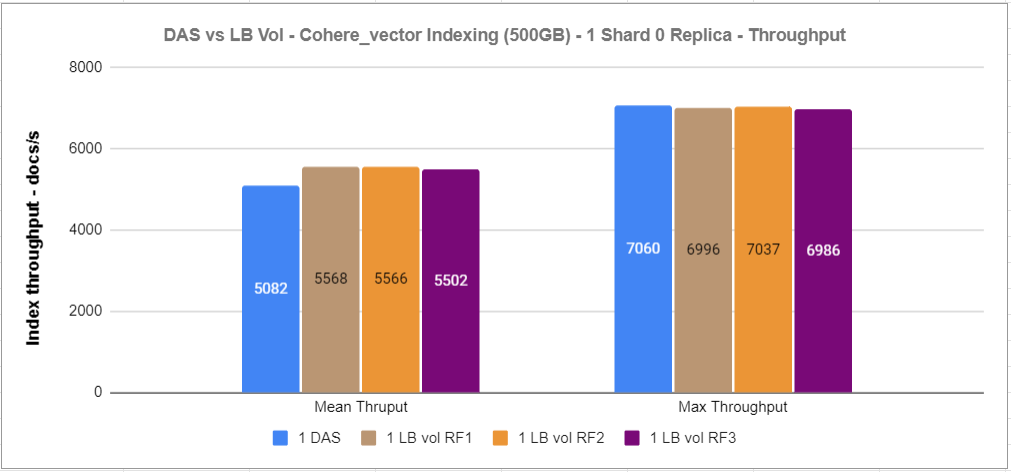
Figure 10: 1xDAS vs 1xRF1 vs 1xRF2 vs 1xRF3 indexing throughput
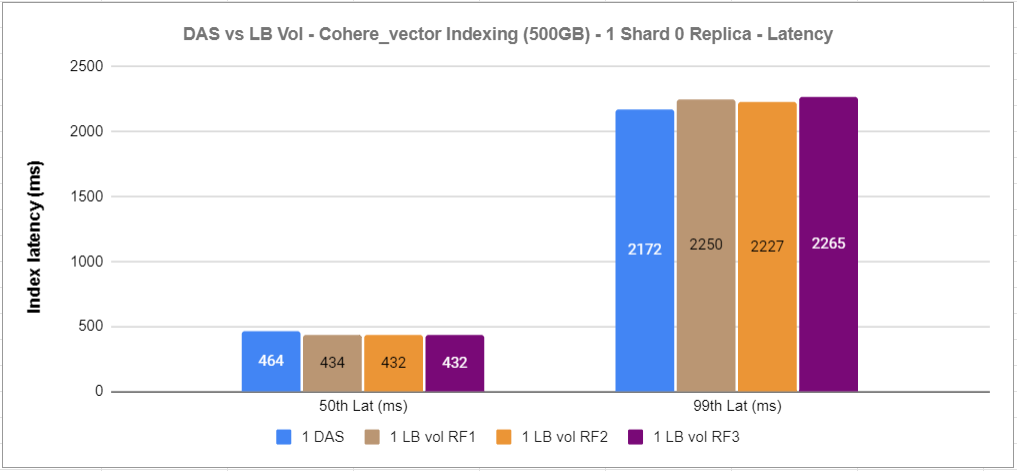
Figure 11: 1xDAS vs 1xRF1 vs 1xRF2 vs 1xRF3 indexing latency
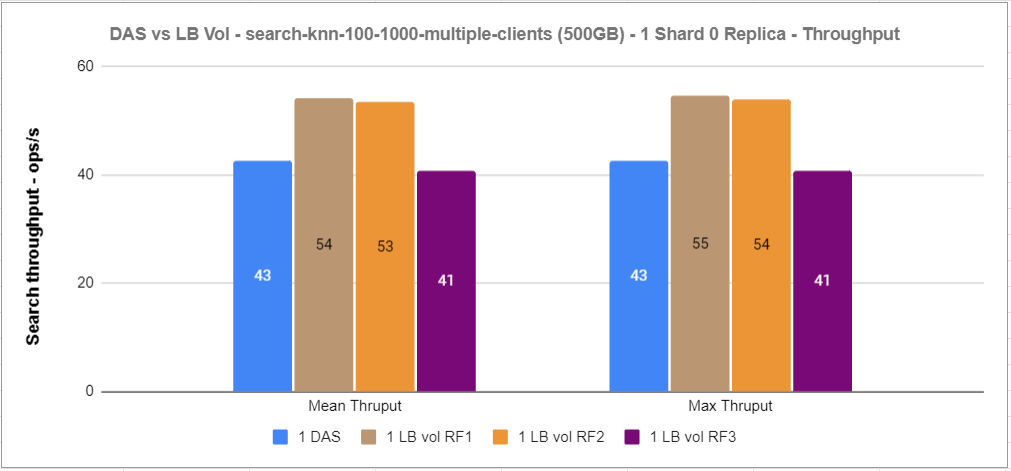
Figure 12: 1xDAS vs 1xRF1 vs 1xRF2 vs 1xRF3 knn-search throughput
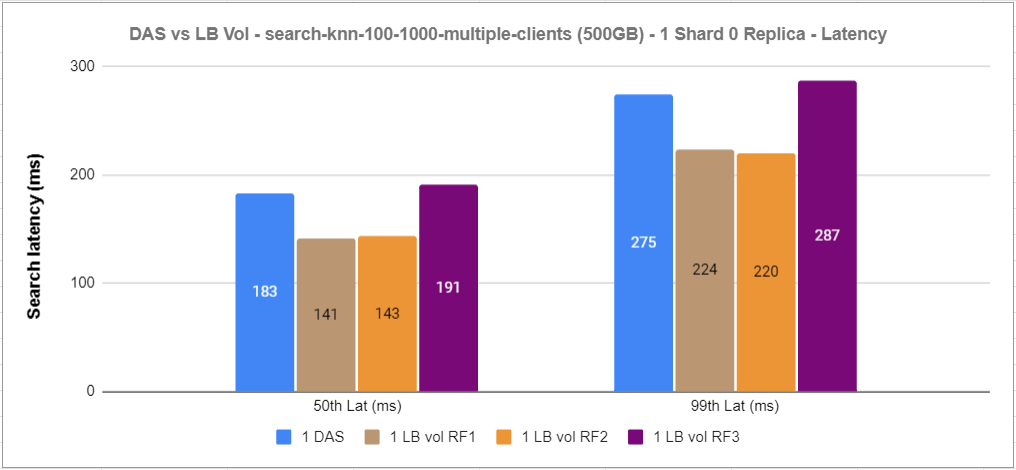
Figure 13: 1xDAS vs 1xRF1 vs 1xRF2 vs 1xRF3 knn-search latency
For this experiment, we noticed that RF1 and RF2 volumes performed better than direct-attached NVMe storage, and that RF3 is not that far behind using the track default settings.
Conclusion
While the performance and scalability of Lightbits’ cloud data platform are clear, it’s important to consider the scale of your Elasticsearch deployment when evaluating cost effectiveness. For smaller Elasticsearch clusters – where data volume and query load are relatively modest – the advanced features and capabilities of Lightbits’ software-defined storage might not be fully utilized. In such scenarios, the investments in software-defined storage might not yield proportional benefits, making traditional direct-attached storage more cost effective.
However, as Elasticsearch clusters scale and the demands for storage increase, the advantages of Lightbits’ software-defined storage become more apparent. For large-scale deployments, where managing data growth, ensuring high availability, and maintaining consistent performance become challenging, Lightbits offers significant value. The ability to scale storage independently of compute resources not only improves performance management but also results in substantial cost savings over time. This is relevant for organizations that anticipate rapid data growth or have fluctuating storage needs.
While Lightbits disaggregated software-defined storage solutions may represent an initial overhead for smaller setups, they are exceptionally well-suited for large, dynamic Elasticsearch clusters where the cost of not scaling efficiently outweighs the initial investment in a more capable storage solution.
Additional Resources

