Why NVMe/TCP is the new iSCSI
There is an increasing demand for NVMe devices in enterprise storage. Not surprising at all, NVMe is becoming the standard interface in the back end of every storage solution, and more and more vendors are working to provide the same interface, NVMe-oF, on the front end.
The ABCs of NVMe Protocols
NVMe can be encapsulated in several transport protocols, including Fibre Channel (FC), InfiniBand, Remote Direct Memory Access on Converged Ethernet (RoCE), and the relative newcomer, simple TCP. This enables organizations to have multiple options on new infrastructure designs and, at the same time, investment protection on existing infrastructures.
FC, for example, has been the standard in every enterprise infrastructure for a long time now. It requires dedicated cabling, host adapters, and switches. It is very expensive in the end, but NVMe/FC is a good compromise if you invested heavily in this technology and want to amortize the existing infrastructure and maybe plan a long-term transition to other types of networks. In this case, the minimal requirement to adopt NVMe/FC is Gen5 16Gb/s FC.
Enterprise organizations have not really adopted InfiniBand. It has huge bandwidth with low latency and is optimized to move small messages quickly. It is one of the most common networks in high-performance computing, and NVMe gives its best on InfiniBand, but, again, if you are an enterprise, this is not for you (and it is highly likely that the storage products you plan to use will have limited support for it, if any).
One of the main advantages of FC and InfiniBand is their lossless nature. In practice, it is the network that cares about the connection and does not lose packets between hosts and storage systems. On the other hand, standard Ethernet is a best-effort network and based on a series of simplified network controls for which packets can be lost on the way. They can be sent again, of course, but this may create performance issues. Converged Ethernet (CE) added more protocols to solve these issues and prioritize specific traffic like storage and close the FC and InfiniBand gap. In particular, the first implementations of CE were necessary to encapsulate FC traffic on datacenter Ethernet (FCoE). The idea behind FCoE was to converge both storage and network on the same wire. It worked but nobody at that time was ready for this kind of change. RoCE is an additional enhancement that simplifies the stack and helps minimize latency. I’ve tried to make this explanation simple and quick, and maybe it is an oversimplification, but this does give you the idea.
Last but not least, there is NVMe/TCP. It just works. It works on existing hardware (not the computer discount switch, of course, but any enterprise switch will do) and standard server NICs. It is not as efficient as the others, but I’d like to get deeper into this before thinking this is not the best option.
Theory Versus Reality
RoCE is great, but it is also really expensive. To make it work, you need specific NICs (network interface adapters) and switches. This means that you can’t reuse the existing network infrastructure, and you need to add NICs to servers that already have NICs, which also limits your options around hardware and introducing lock-in on specific network adapters.
Alongside the cost per port, you need to consider that two 100Gb/s NICs (necessary for high availability) will provide 200Gb/s per node. This is a considerable speed, do you really need it? Are your applications going to take advantage of it?
But there is more. Let’s take a look at all the available options:
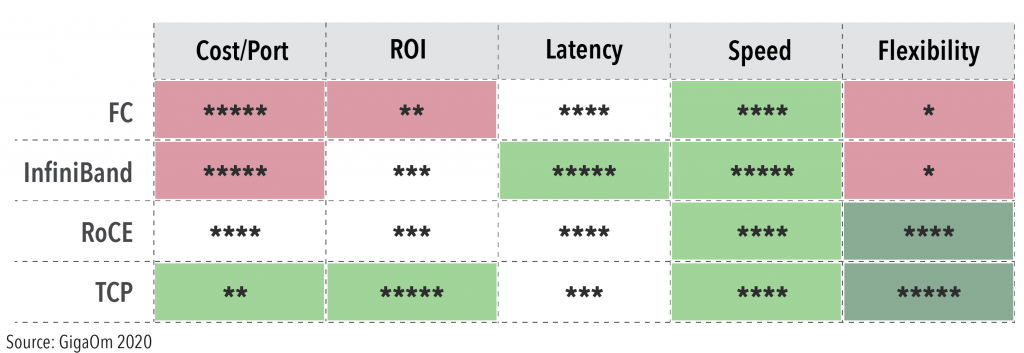
If we compare all the available options in the market, you’ll note that NVMe/TCP has many advantages and in the real world, it doesn’t have any main drawback. It shines when it comes to cost per port and ROI. Speed aligns with other solutions. The only parameter that is not on top compared to the others is latency (more on this soon). But flexibility is absolutely another aspect not to underestimate. In fact, you can use existing switches, configurations and the NICs that come installed in your server and adapt along the way.
Of Latency and Flexibility
Yes, NVMe/TCP has a higher latency than the others. But how much? And how does it really compare with what you have today in your data center?
A recent briefing I had with Lightbits Labs featured a series of benchmarks that compare traditional Ethernet-based protocol (iSCSI) with NVMe/TCP. The results are quite impressive, in my opinion, and this should give you a good idea about what to expect from the adoption of NVMe/TCP.
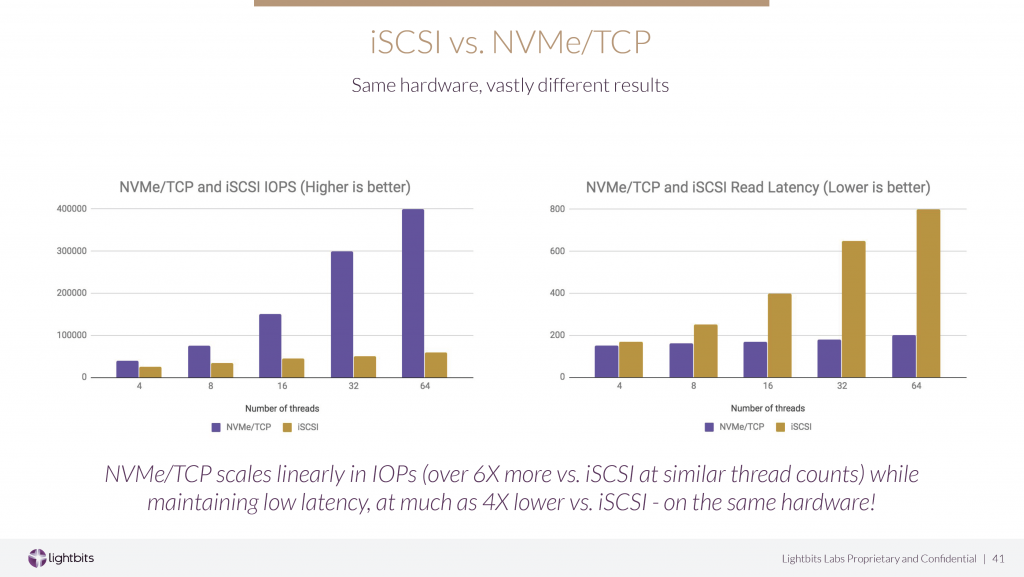
From this slide you can see that, by just replacing iSCSI with NVMe/TCP, the efficiency introduced by the new protocol stack reduces latency and keeps it always under 200µSecs, even if the system is particularly stressed. Again, same hardware, improved efficiency.
Yes, with NVMe/FC or NVMe/RoCE, you can get even better latency, but we are talking about 200µS, and there are very few workloads and compute infrastructures that truly need a latency that is lower than 200µS. Am I wrong?!
The low cost of NVMe/TCP has another important advantage. It allows the modernization of legacy FC infrastructures at a fraction of the cost of other options described in this article. Legacy 8/16Gb/s FC HBAs and switches could be replaced by standard 10/25 Gb/s NICs and ethernet switches. This would simplify the network and its management while decreasing support and maintenance costs.
Closing the Circle
NVMe/TCP is one of the best options to adopt NVMe-oF. It is the least expensive and the most flexible of the bunch. What’s more, it’s performance and latency compare quite well to traditional protocols. Yes, TCP adds a little bit of latency to NVMe, but for most enterprise workloads we are talking about a huge improvement in moving to NVMe anyway.
From my point of view, and I already said this multiple times, NVMe/TCP will become the new iSCSI in terms of adoption. Ethernet hardware is very powerful and with optimized protocols it provides incredible performance without additional cost or complexity. The fact is not all servers in your datacenter will need ultimate performance, and with NVMe/TCP you have multiple options to address every business need. To be honest, you can easily reduce the performance gap to a minimum. For example, Lightbits Labs can take advantage of ADQ technology from Intel to further improve latency while keeping costs down and avoiding lock-in.
In the end, it all comes to TCO and ROI. There are very few workloads that might need the latency offered by RoCE, for the rest there is NVMe/TCP—especially if we consider how easy it is to adopt and run on Ethernet infrastructures already in place.
Original blog post: https://gigaom.com/2020/12/18/nvme-of-for-the-rest-of-us/
