Lightbits Labs is proud to be a supporting organization of MLCommons and participate in the MLperf Storage V1.0 benchmark, demonstrating our disaggregated, software-defined block storage solution’s ability to meet the demanding performance and scaling requirements of machine learning workloads.
Lightbits Labs is proud to be a supporting organization of MLCommons and participate in the MLperf Storage V1.0 benchmark, demonstrating our disaggregated, software-defined block storage solution’s ability to meet the demanding performance and scaling requirements of machine learning workloads.
MLPerf Storage is a benchmark suite designed to measure the performance of storage systems supporting machine learning workloads. It is a collaborative effort between industry leaders and researchers to establish a standardized way to evaluate the capabilities of different storage solutions for AI and ML applications.
The benchmark suite consists of a set of workloads that simulate typical ML training scenarios, such as loading large datasets, performing iterative training steps, and saving intermediate results. Version v1.0 of the benchmark includes models for Cosmoflow, Resnet50, and 3D U-Net and simulates modern industry-leading accelerators, the A100s and H100s. These workloads are executed on different storage systems, and their performance metrics, including throughput, latency, and energy efficiency, are measured and compared. In addition to these metrics, the benchmark also focuses on measuring accelerator utilization to validate that storage is not the cause of performance bottlenecks or that the benchmark isn’t waiting for the storage and wasting expensive GPU cycles. With faster and higher-performance storage systems, the benchmark is capable of achieving higher accelerator utilization and better utilization of GPUs.
In this submission, Lightbits software-defined storage delivered impressive results across a variety of ML models, including 3D U-NetCosmoflow. Our solution, featuring NVMe/TCP shared block storage, efficiently distributed data and workloads across multiple Lightbits storage servers, leveraging features like snapshotting and cloning.
Using a minimal configuration of three commodity storage servers and in partnership with Micron, we achieved outstanding performance for both 3D U-Net and ResNet-50. The storage servers with Micron 7500 NVMe SSDs were able to keep pace with the demanding I/O patterns of these ML models, even when paired with 6 client servers running highly utilized accelerators, there is still an appetite to support additional clients.
For the Cosmoflow model, which is particularly sensitive to client CPU performance, Lightbits Labs not only provides high throughput, it also demonstrates its ability to deliver consistent low-latency response times required for these clients in order to meet high utilization of accelerators tested in the benchmark.
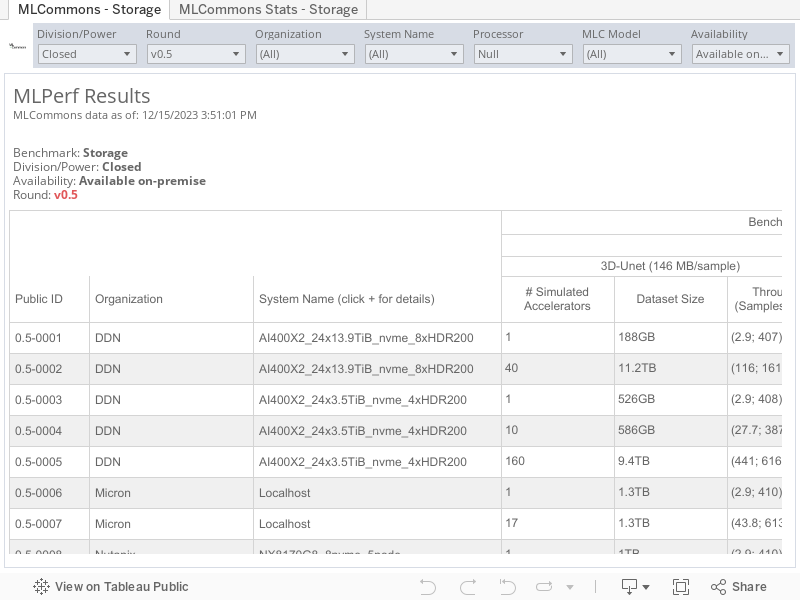
The finalized and validated results by MLCommons Storage are below.
- Cosmoflow – A CPU-intensive model where 70% accelerator utilization is required by MLCommons to be considered a successful execution. Utilizing just 3 clients, Lightbits was able to deliver over 16Gib/s of throughput with A100s and nearly 19Gib/s with H100s. With tuning, the benchmark achieved consistent 71% of accelerator utilization. Utilizing just 3 clients, we are tapping into a faction of the Lightbits cluster’s capabilities; there is room for additional clients and growth.
- Resnet-50 – This model is relatively large in size and has high computational complexity. With consistent 94% of accelerator utilization across 6 clients, Lightbits averaged 28Gib/s with A100s and about 39Gib/s with H100 accelerators while processing 244k and 337k samples per second respectively. Impressive results are being delivered by a minimum configuration Lightbits cluster.
- Unet3D – A large dataset model of 3D medical images for segmentation with sample sizes as large as 140MB each. Typical processing times for each sample on H100s are 0.320 seconds and A100s are 0.636 seconds; with the addition of Lightbits storage and network access time, the average time for samples to be processed were 0.329 seconds and 0.644 seconds respectively. Lightbits demonstrated minimal overhead with processing times for each sample increasing only slightly compared to typical accelerator processing times.
| Model | Accelerator Type | # of Accelerators | Samples per Second | Throughput (MiB/s) | Dataset Size (GiB) |
|---|---|---|---|---|---|
| Cosmoflow | A100 | 45 | 5,910 | 15,943 | 7,680 |
| Cosmoflow | H100 | 33 | 6,700 | 18,074 | 7,680 |
| Resnet-50 | A100 | 282 | 244,561 | 26,742 | 15,360 |
| Resnet-50 | H100 | 198 | 337,592 | 36,915 | 15,360 |
| 3D U-Net | A100 | 24 | 224 | 31,432 | 15,360 |
| 3d U-Net | H100 | 12 | 241 | 33,797 | 15,360 |
Key takeaways from our MLperf Storage submission include:
- High Performance: Lightbits is capable of maintaining client accelerator utilization at a consistent 90% and above for Unet3d and Resnet-50 models and 70% and above for Cosmoflow model. In most cases, Lightbits was constantly delivering 30GB/s of storage activity concurrently with Lightbit’s minimum configuration of 3 storage servers.
- Scalability: Lightbits can easily scale to meet growing performance requirements by adding additional storage nodes to the cluster. Customers can reduce TCO by starting with a minimum configuration of 3 storage servers and only buy/scale when the performance demands it.
- Efficiency: Lightbits disaggregated, software-defined architecture runs on commodity hardware providing a cost-effective solution.
- Flexibility: Lightbits supports a wide range of ML workloads, ensuring that our customers can optimize their storage infrastructure for their specific needs.
The benchmark results demonstrate Lightbits software-defined storage performance benefits for ML workloads. With ongoing software updates and optimizations, Lightbits Labs expects continued improvements in performance and efficiency that empower organizations to accelerate their AI and ML initiatives.
The full results are below or go to: https://mlcommons.org/benchmarks/storage/